
Puppet für Entwickler
Kein Administrator wird heute einen Server manuell konfigurieren. Stattdessen wird die gewünschte Konfiguration mit Systemen wie Puppet, Chef oder Ansible “programmiert”. Mit einem Programmaufruf wird ein neues System in den gewünschten Zustand gebracht. Diese Art der Konfiguration ist nicht nur für den Betrieb sondern auch für den Entwickler interessant. Auch er möchte die Vorteile von schnell gebauten Systemen und reproduzierbaren Konfigurationen nutzen. Im folgenden wird das Konfigurationsmanagement-System Puppet vorgestellt. Anhand von Beispielen aus der Welt der Software-Entwicklung wird anschließend die Konfiguration von Diensten mit Puppet vorgestellt.
Was ist Puppet?
Puppet ist eine Software zur automatisierten Konfiguration von Servern und darauf laufenden Diensten. Sie wurde 2005 von Luke Kanies in Ruby programmiert. Luke war mit dem damals bereits verfügbaren System CFEngine nicht zufrieden. Er programmierte daraufhin seine Version eines Konfigurations-Management-Tools. Puppet ist von Anfang an OpenSource. Die verwendete Lizenz wurde 2011 von der GPL auf die Apache Lizenz geändert. Seit dieser Zeit gibt es eine kommerzielle Enterprise Version von Puppet. Die OpenSource und die Enterprise Version unterscheiden sich nicht im Funktionsumfang.
Puppet wird primär zur Konfiguration von “unix-oiden” Systemen eingesetzt. Seit einiger Zeit können auch Systeme unter Windows mit Puppet verwaltet werden. Durch den grundsätzlichen anderen Aufbau von Windows im Vergleich zu Linux, MacOS X & Co. lassen sich die Konfigruationen aber nicht untereinander austauschen. Im folgenden Text wird die Konfiguration von Systemen unter Linux beschrieben.
Von Puppet Labs werden Pakete für die folgenden Distributionen zur Verfügung gestellt:
-
RedHat, CentOS, Fedora
-
Debian, Ubuntu
SuSE kümmert sich selbst um die Bereitstellung von Paketen. Für Arch Linux stellt die Community Pakete bereit.
Deklaration der Konfiguration
Puppet arbeitet deklarativ. Es werden nicht Schritte und Operationen beschrieben, die zum Erreichen der Konfiguration durchgeführt werden müssen. Stattdessen wird mittels einer DSL (domain specific language) der gewünscht Ziel-Zustand der Konfiguration beschrieben. Puppet ermittelt aktuellen Ist-Zustand des Systems und vergleicht ihn mit dem definierten Soll-Zustand. Aus der Differenz werden die aufzuführenden Operationen ermittelt und ausgeführt.
Puppet arbeitet dabei idempotent. Auch bei mehrfacher Ausführung von Puppet werden keine Änderungen am System durchgeführt, wenn der definierte Soll-Zustand erreicht ist. Puppet führt nur die notwendigen Änderungen dadurch um den Soll-Zustand zu erreichen. Dadurch werden bei jedem Lauf von Puppet auch alle in der Zwischenzeit manuell vorgenommenen Änderungen rückgängig gemacht.
Dateien und Konfigurationen die nicht in Puppet beschrieben sind, werden von Puppet nicht beeinflusst. So können neben den mit Puppet verwalteten Diensten weiterhin herkömmlich konfigurierte Dienste betrieben werden.
Die Architektur von Puppet
Puppet besteht aus der zentralen Server-Komponente dem Master und dem auf den zu konfigurierenden Systemen installierten Agent.
Der Master wird auf einem eigenen Server im Netzwerk ausgeführt. Er kümmert sich um die Erstellung des Catalogs aus den Modulen und Manifesten. Mittels der Manifeste wird die gewünschte Konfiguration beschrieben.
Der Agent wird auf allen zu konfigurierenden Systemen ausgeführt. Er konfiguriert das System mit den Informationen aus dem Catalog, die ihm der Master übermittelt hat. Der Catalog definiert den gewünschten Soll-Zustand, der auf dem System des Agents hergestellt werden soll.
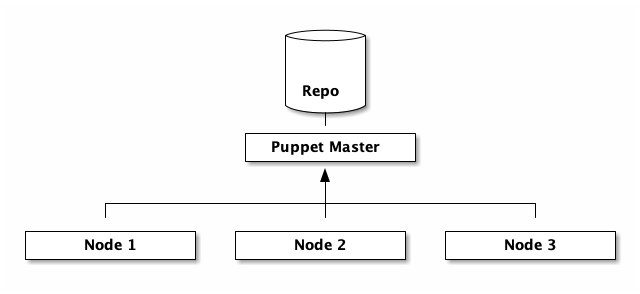
Die Kommunikation zwischen Agent und Master wird immer vom Agent initiiert. Die Kommunikation erfolgt über HTTPs. Zur Absicherung der Kommunikation sind sowohl der Agent als auch der Master mit Zertifikaten versehen. Die notwendige CA wird von Puppet selbst verwaltet. Ohne gültiges Zertifikat der Puppet CA erhält kein Agent eine Konfiguration.
Die in der DSL von Puppet definierte Konfiguration wird im Puppet Repository gespeichert. Dabei handelt es sich um eine vorgegebene Verzeichnisstruktur in der die einzelnen Module und Manifeste gespeichert werden.
| Es besteht die Möglichkeit Puppet auch ohne einen Master zu betreiben. Dann übernimmt der Agent auch die Erstellung des Catalogs. In diesem Fall muss der Agent Zugriff auf das Puppet Repository haben. |
Der Puppet Lauf
Der Agent kann zeitgesteuert z.B. alle 30 Minuten von selbst starten. Neben dem manuell Start des Agents wird oft auf Cron zur Steuerung der Ausführung zurückgegriffen.
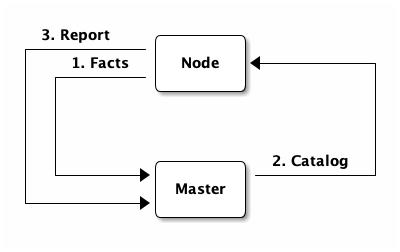
Ein Puppet-Lauf unterteilt sich in die folgenden Schritte:
- Facts ermitteln
-
Der Agent ermittelt den Wert / Zustand aller sogenannten Facts. Dabei handelt es sich um Werte, die den aktuellen Zustand des Systems beschreiben. Es gibt Facts über die konfigurierten IP-Adressen, die Anzahl und Art der verfügbaren CPUs und Informationen über das Betriebssystem. Neben diesen vorgegebenen Facts können eigene Facts erstellt werden um z.B. den Stage des Systems (Entwicklung, Integration, Abnahme, …) oder die Location des Servers zu ermitteln.
- Facts an Master senden
-
Die gesammelten Facts werden mittels eines POST Requests an den Puppet Master übertragen. Dieser übermittelt die Facts an evtl. vorhandene weitere Systeme (z.B. Puppet DB, Foreman) und nutzt die Werte selbst zur Erstellung des Catalogs.
- Catalog erstellen
-
Der Master erstellt aus allen dem Node zugeordneten Modulen den Catalog. Dieser beinhaltete alle definierten Resourcen und deren Attribute. In den Modulen kann in Abhängigkeit der ermittelten Facts die Konfiguration / der Catalog angepasst werden.
- Catalog an Agent senden
-
Der vom Master erstellte Catalog wird als Antwort auf den POST Request an den Agent / Client zurück geliefert. Ist es bei der Erstellung des Catalogs zu einem Fehler gekommen wird stattdessen ein HTTP Status Code 400 an den Agent übermittelt.
- Catalog anwenden
-
Der Agent wendet den vom Master empfangenen Catalog auf das Systema an. Er vergleicht die im Catalog definierten Resourcen und deren Attribute mit den zugehörigen Resourcen auf dem System und führt evtl. notwendige Änderungen durch.
- Report an Master senden
-
Bei der Anwendung des Catalogs wird ein Report erstellt. Dieser Report wird vom Agent als letzte Aktion wieder mittels eines POST Request an den Master übermittelt.
Die Puppet Language
Mit der Puppet Language wird die Konfiguration beschrieben. Das zentrale Element der Puppet Language ist die Ressource. Eine Resource ist die kleinste zu definierende Einheit einer Konfiguration. Als Resource wird z.B. eine Datei, ein Benutzer oder ein Dienst definiert. Jede Resource wird mit einem eindeutigen Namen und ein oder mehreren Attributen definiert. Über die Attribute wird die Resource genauer spezifiziert.
Im folgenden Beispiel wird eine File-Ressource definierte.
Die Datei /etc/default/jenkins soll auf dem System vorhanden sein (ensure present).
Die Datei hat als Besitzer den Benutzer root.
Die Datei ist der Gruppe root zugeordnet.
Die Zugriffsrechte werden auf 0644 (rw-r—r--) gesetzt.
Die Datei soll den Inhalt der für das Modul Jenkins hinterlegten Datei etc/default/jenkins haben.
file { '/etc/default/jenkins':
ensure => present,
source => 'puppet:///modules/jenkins/etc/default/jenkins',
owner => 'root',
group => 'root',
mode => '0644',
}In Abhängigkeit von Facts oder selbst ermittelten Werten, können einzelnen Resourcen zum Catalog hinzugefügt oder von diesem entfernt werden. So werden im folgenden die Ressourcen nur dem Catalog hinzugefügt, wenn das Betriebssystem des Systems Debian ist.
if $::os['name'] == 'Debian' {
...
}Neben Conditionals zur bedingten Definition von Ressourcen definiert die Puppet Language verschiedene Elemente zur Kombination von Ressourcen zu umfangreicheren Elementen.
Werden mehrere Ressourcen zu einer class zusammen gefasst, können diese an einem Stück einem System zugewiesen werden. Einem System kann dabei immer nur eine Instanz einer Klasse zugeordnet werden. Eine weitere Möglichkeit zur Zusammenfassung von Ressourcen ist ein define. Im Gegensatz zu einer Klasse können einem System mehrere Instanzen eines Defines zugeordnet werden. Klassen konfigurieren somit nur einmal auf dem System vorhandene Systeme wir z.B. den Apache httpd Daemon. Mit Defines werden mehrfach vorhandene Elemente wie z.B. Virtuelle Hosts eines Apache httpd beschrieben.
Module können über die Puppet Forge geteilt werden. Mit der Forge steht eine Sammlung von vorgefertigten Konfiguration zur Verfügung. Das Rad muss nicht immer neu erfunden werden. Man kann die Forge mit einer Sammlung an Bibliotheken vergleichen.
Neben der Beschreibung der Konfiguration werden mittels der Puppet Language auch die Zuordnungen von Klassen oder Modulen zu den zu konfigurierenden Systemen definiert.
Die Systeme werden durch einen Node identifiziert.
Neben dem Namen des Systems können hier reguläre Ausdrücke verwendet werden, um die gleiche Konfiguration mehreren System zuzuordnen.
Dem Node werden dann mittels der Funktion include die Module zugeordnet.
node buildserver.example.org {
include 'java'
include 'jenkins'
}
node /server[1-3].example.org/ {
include 'jboss'
}Mit der ersten Node-Definition werden dem System buildserver.example.org die beiden Module Java und Jenkins zugeordnet.
Die zweite Definition umfasst die Server server1.example.org, server2.example.org und server3.example.org. Diesen Servern wird das Modul Jboss zugeordnet.
Trennung von Code und Daten
Mit den Elementen der Puppet Language können so gut wie alle Konfigurationen beschrieben werden. Ohne weitere Hilfe werden jedoch mit der Sprache das Wie - der Code - mit dem Was - den zugehörigen Daten - vermischt.
- Code
-
Aus welchen Elementen besteht eine Konfiguration? Welche Pakte, Dateien und Dienste müssen verwaltet werden?
- Daten
-
Mit welchen Konfigurationswerten muss in einer Konfigurationsdatei gearbeitet werden? Welche Werte sind einzutragen?
Mittels der hierarchischen Datenbank Hiera können in Puppet die Konfigurationswerte z.B. in YAML-Dateien ausgelagert werden. Durch verschiedene Hierarchien können die Werte für einen Rechner, eine Rechnergruppe oder ein ganzen Netzwerk gültig sein. Änderungen am Wert einer Konfiguration bedingen nicht mehr eine Änderung des Codes und umgekehrt.
Was kann ich mit Puppet tun?
Nach dieser kurzen Einführung in Puppet werden im folgenden einige Beispiele für Konfigurationen gegeben. Sie zeigen, wie Puppet ein Team bei der Entwicklung von Software unterstützen kann.
Soweit möglich und sinnvoll wird für die gezeigten Konfigurationen auf fertige Module aus der Puppet Forge zurück gegriffen. In der Forge sind inzwischen viele Module in hervorragender Qualität verfügbar. Der Aufwand zur Einrichtung der gewünschten Software ist damit sehr gering.
Kern der Infrastruktur eines jeden Software-Entwicklungs Projekts ist der Build-Server. Durch den Server wird der von den Entwicklern erstellte Quellcode compiliert, getestet und mit verschiedenen Verfahren geprüft. Häufig wird hierzu der Continuous Integration Server Jenkins verwendet. Dieser benötigt neben einer installierten Java Runtime noch weitere Programme. Mit Puppet kann eine entsprechende Konfiguration erstellt und verwaltet werden.
JDK
Eine der Grundlagen für den Build-Server ist ein installiertes JDK. Das OpenJDK kann auf allen Linux-Systemen direkt aus den Repository der Distribution installiert werden. Das Oracle JDK darf seit einer Änderung der Operating System Distributor License for Java nicht mehr von den Distributionen umpaketiert werden. Dieses JDK muss entweder direkt von der Oracle Homepage heruntergeladen oder in einem lokalen Repository zur Verfügung gestellt werden.
Puppet bietet mit der Resource file die Möglichkeit Dateien auf den System zu kopieren und diese hierzu auf dem Puppet Master zur Verfügung zu stellen.
Der in den Puppet-Master integrierte Datei-Server ist aber nicht für umfangreiche Dateien ausgelegt.
Somit wird nicht empfohlen umfangreiche Dateien wie z.B. das JDK von Java über diesen Weg zu verteilen.
|
Die Konfiguration des JDK erfolgt am einfachsten mit dem Java Modul von Puppet Labs puppetlabs-java aus der Forge.
include 'java'Über Hiera wird das Modul konfiguriert. In unserem Fall installieren wir das JDK der Distribution (OpenJDK).
---
java::distribution: 'jdk'Build-Tool
Das Build-Tool - in unserem Falle Maven - kann ebenfalls mit Puppet verwaltet werden.
In vielen Distributionen ist eine (evtl. alte) Version von Maven zur Installation verfügbar.
Mittels des Puppet-Moduls maestrodev-magen kann neben der Installation auch die Konfiguration der settings.xml erfolgen.
include 'maven'
maven::settings { 'global-settings':
mirrors => hiera('maven::mirrors'),
servers => hiera('maven::servers'),
}Die Konfiguration der Mirrors und Servers erfolgt gemäß der Trennung von Code und Daten in Hiera.
Durch die folgenden Einträge in Hiera wird in der settings.xml ein Proxy-Server für das Central-Repository konfiguriert.
Weiterhin werden die beiden (lokalen) Repositories Snapshots und Releaeses definiert.
---
maven::maven::version: '3.2.5'
maven::mirrors:
- 'central':
id: 'central'
url: 'https://local.nexus.example.com/nexus/content/groups/public/'
mirrorOf: 'central'
maven::servers:
- 'snapshots':
id: 'snapshots'
url: 'https://loca.nexus.example.com/nexus/content/repositories/snapshots'
active: 'true'
username: 'deployment'
password: 'geheim'
- 'release':
id: 'releases'
url: 'https://loca.nexus.example.com/nexus/content/repositories/releases'
active: 'true'
username: 'deployment'
password: 'nochmehrgeheim'version control system
Die Installation und Konfiguration von Git als Version Control Systems erfolgt direkt ohne die Verwendung eines Moduls aus der Forge.
Die folgenden Resourcen sorgen dafür, dass Git aus dem Repository der Distribution installiert wird (package Resource).
Im Home-Directory von Jenkins werden die wichtigsten Einstellungen für Git in der Datei .gitconfig (file Resource) abgelegt.
package { 'git':
ensure => installed,
}
file { '/var/lib/jenkins/.gitconfig':
ensure => file,
content => template(git/gitconfig.erb),
owner => 'jenkins',
groupe => 'jenkins',
mode => '0644',
}Der Inhalt der Konfigurationsdatei wird bei der Erstellung des Catalog aus dem Template gitconfig.erb ermittelt.
Mit Templates vom Typ erb (embedded ruby) kann der Inhalt einer Datei aus festem Text und Platzhaltern für Werte erstellt werden.
Die Werte können aus Variablen der Puppet Language, aus Facts oder aus Hiera stammen.
In unserem Beispiel wird als Domain-Part der E-Mail Adresse der Fact fqdn (fully qualified domain name) des Nodes eingesetzt.
[user]
name = Build Server
email = jenkins@<%= @fqdn %>
[push]
default = currentJenkins
Für die abschließende Konfiguration unseren CI-Servers Jenkins steht das Modul rtyler-jenkins in der Forge zur Verfügung.
Der Status eines “Puppet Approved” Moduls stellt sicher, dass sich der Autor des Moduls an alle Konventionen von Puppet Labs gehalten hat.
Die gesamte Konfiguration der von Jenkins benötigten Plug-Ins erfolgt bei diesem Modul in Hiera. Das Modul kümmert sich aber auch um die Installation von Jenkins selbst. In unserem Fall deaktivieren wir die Installation von Java, da wir diese selbst vorgenommen haben. Weiterhin haben wir uns für die Installation der LTS Version von Jenkins entschieden.
Neben den gewünschten Plug-Ins selbst müssen wir in der derzeitigen Version des Moduls auch die Abhängigkeiten eines Moduls aufführen. Das Update der Plug-Ins muss ebenfalls über Puppet erfolgen. Zwar lassen sich über die in Jenkins integrierte Update-Funktion die Module aktualisieren. Beim nächsten Puppet-Lauf werden aber wieder die in Hiera eingetragenen Versionen der Plug-Ins installiert.
include 'jenkins'---
jenkins::install_java: false
jenkins::lts: true
jenkins::config_hash:
JENKINS_HOME:
value: '/srv/jenkins'
jenkins::plugin_hash:
git:
version: '2.3.4'
credentials:
version: '1.20'
ssh-credentials:
version: '1.10'
git-client:
version: '1.15.0'
scm-api:
version: '0.2'
matrix-project:
version: '1.4'
mailer:
version: '1.11'weitere Server
Neben diesen Kernbestandteilen eines Build-Servers können weitere Komponenten des Buld-Servers wie z.B. SonarQube oder Gerrit mit Puppet konfiguriert werden. Auch bietet es sich an nicht nur den Build-Server, sondern auch alle anderen Server des Teams mit Puppet zu konfigurieren.
Die vom Team erstellten Artefakte werden auf Testsystem deployt und dort automatisiert und / oder manuell getestet. Puppet ist ideal dafür geeignet diese System zu konfigurieren. Wird ein Server neu gebaut, wird mit einem Puppet-Lauf das System in den definierten Zustand versetzt. Damit ist nur es ein kleiner Schritt die für die Testsysteme genutzte Konfiguration auch auf alle weiteren Stages bis hin zur Produktion anzuwenden. Wenn der Betrieb (Ops) neben dem Artefakt auch die Konfiguration von den Entwicklern (Dev) übernimmt und evtl. angpeasst verwendet, ist ein großer Schritt in Richtung DevOps getan.
Dieser Artikel ist auch im Magazin “Java aktuell – Das iJUG Magazin” 01-2016 erschienen.